카운팅 정렬
항목들의 순서를 결정하기 위해 집합에 각 항목이 몇 개씩 있는지 세는 작업을 하여, 선형 시간에 정렬하는 효율적인 알고리즘
제한 사항
- 정수나 정수로 표현할 수 있는 자료에 대해서만 적용 가능
- 카운트들을 위한 충분한 공간을 할당하려면 집합 내의 가장 큰 정수를 알아야 한다.
- 시간 복잡도는 O(n + k): n은 리스트 길이, k는 정수의 최대값
1단계
data에서 각 항목들의 발생 회수를 세고, 정수 항목들로 직접 인덱스 되는 카운트 배열 counts에 저장한다.
data가 [0, 4, 1, 3, 1, 2, 4, 1] 이라면
counts는 [1, 3, 1, 1, 2] 가 된다.
이 뜻은 counts의 각 인덱스 번호가 data에 있는 정수가 된다.
즉, 위의 counts에서 0은 1개, 1은 3개, 2는 1개.. 이런 식으로 표현이 된 것이다.
2단계
정렬된 집합에서 각 항목의 앞에 위치할 항목의 개수를 반영하기 위해 counts의 원소를 조정한다.
for문을 돌려 count의 1번 인덱스 부터 전의 인덱스 값을 더해 준다.
counts = [1, 3, 1, 1, 2]에서
counts = [1, 4, 5, 6, 8]이 된다.
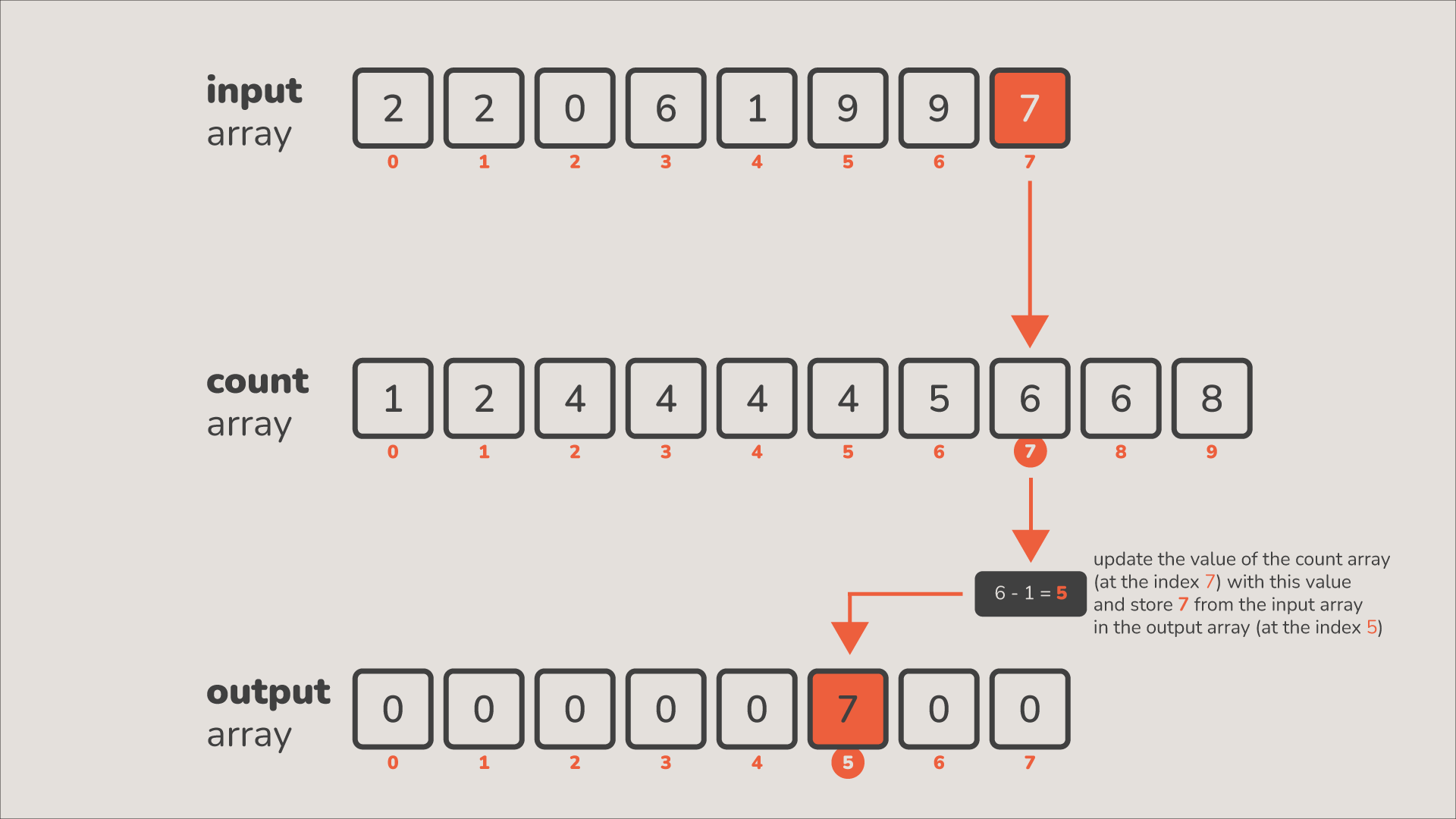
3단계
이제 2단계를 지난 counts를 활용해 data를 정렬한다.
data의 마지막 부터 회문을 돌려 그 값을 인덱스로 표현한 counts에 1을 빼주고,
counts의 그 인덱스에 있는 숫자를 인덱스로 하여 data에 넣어준다.
글로 표현 하면 설명이 어렵기 때문에 직접 보자
이런 식으로 정렬이 된다.
그럼 이 과정을 코드로 표현해 보자
nums = list(map(int, input().split())) # 원래의 data
N = len(nums)
arr = [0]*N # 정렬된 값을 넣을 list
c = [0] * (max(nums) + 1) # counts에 넣을 list
for num in nums: # 1단계
c[num] += 1
for i in range(1, len(c)): # 2단계
c[i] += c[i-1]
for i in range(len(arr)-1, -1, -1): # 3단계
c[nums[i]] -= 1
arr[c[nums[i]]] = nums[i]
print(*arr)
카운팅 정렬의 평균, 최악 수행시간은 O(n+k)이고, n이 기뵤적 작을때만 가능하다는 단점이 있다.
'알고리즘 개념' 카테고리의 다른 글
| Stack 스택 (파이썬) (0) | 2022.09.01 |
|---|---|
| 트리 순회 코드 (파이썬) (0) | 2022.08.28 |
| 2차원 리스트 지그재그 순회 (파이썬) (0) | 2022.08.21 |
| 투 포인터 (파이썬) (0) | 2022.08.06 |
| WHO AM I ? (0) | 2022.07.25 |